5 Khung đánh giá mô hình
Mục tiêu là phát triển một mô hình có khả năng dự đoán tốc độ mài mòn tối đa (mm / Mt) từ các biến giải thích và ước tính hiệu suất của nó trên băng tải ngoài mẫu. Hiệu suất dự đoán trong bài viết này được đo dưới dạng sai số bình phương trung bình căn (RMSE) cho các dự đoán dựa trên mô hình băng chuyền không thấy trong đào tạo mô hình. Chúng tôi xếp hạng các mô hình theo tỷ lệ phần trăm cải thiện (giảm) trong RMSE so với các mô hình rỗng không có thông tin (chỉ đơn giản là dự đoán tỷ lệ hao mòn trung bình). RMSE được chọn để dễ giải thích (đơn vị của nó là mm / Mt), và vì nó là số liệu phổ biến trong phân tích hồi quy. Phần trăm cải tiến so với thuật toán null được bao gồm để cung cấp mức hiệu suất cơ bản và để định lượng khả năng dự đoán bổ sung của một mô hình.
Chúng tôi sử dụng khung xác nhận chéo để kiểm tra hai thuật toán mô hình hóa: hồi quy tuyến tính (bình phương nhỏ nhất thông thường) và rừng ngẫu nhiên. Khung được trình bày trong bài viết này có thể được áp dụng để ước tính hiệu suất của bất kỳ loại thuật toán nào để xây dựng mô hình dự đoán. Hồi quy tuyến tính được chọn vì tính đơn giản và phổ biến trong các vấn đề dự đoán, và rừng ngẫu nhiên được đưa vào để kiểm tra xem liệu cách tiếp cận mô hình phi tuyến, linh hoạt hơn có tạo ra các dự đoán tốt hơn cho vấn đề này hay không. Mục đích không phải là đưa ra tuyên bố dứt khoát về hiệu suất so sánh của hồi quy tuyến tính và rừng ngẫu nhiên, cũng không phải để tìm ra mô hình "tốt nhất" thông qua điều chỉnh rộng rãi, mà là để chứng minh cách khung đánh giá mô hình này có thể được sử dụng để so sánh các thuật toán mô hình,
5.1 Xác thực chéo k lần lặp lại
Để ước tính sai số dự đoán ngoài mẫu, một mô hình cần được đánh giá dựa trên dữ liệu không được sử dụng để xây dựng mô hình (Hastie et al., 2009 ; Hurvich và Tsai, 1990 ). Chúng tôi sử dụng xác thực chéo k -fold lặp đi lặp lại , bao gồm việc chia nhỏ dữ liệu thành các tập con có kích thước gần bằng nhau. Một tập hợp con duy nhất được đặt làm tập kiểm tra và các tập hợp con còn lại được sử dụng như một tập huấn luyện để phù hợp với một mô hình. Hàm mất mát (trong trường hợp của chúng tôi là RMSE) được đánh giá trên tập thử nghiệm. Điều này được lặp lại cho mỗi tập hợp con để tạo ra các giá trị hàm mất mát. Để có độ chính xác cao hơn, toàn bộ quá trình được lặp lại nhiều lần với các phần chia khác nhau, dẫn đếnmất các giá trị hàm. Trung bình cộng của tập hợp này được coi là ước tính của sai số dự đoán ngoài mẫu cho một thuật toán phù hợp với mô hình; chúng tôi gọi giá trị này là thống kê xác thực chéo. Độ lệch chuẩn (SD) của các giá trị hàm mất mát cũng được tính toán để cung cấp một thước đo về độ ổn định hoạt động của mô hình.
Chúng tôi kỳ vọng tỷ lệ hao mòn của các
băng tải khác nhau từ cùng một băng tải có mối tương quan cao. Điều này có thể dẫn đến một nguồn tiềm ẩn sai lệch trong kết quả nếu các băng tải khác nhau từ cùng một băng tải xuất hiện trong cả tập huấn luyện và thử nghiệm trong quá trình xác nhận chéo. Để loại bỏ điều này, chúng tôi tạo các tập hợp con bằng cách xáo trộn các ID băng tải và ghép nối từng ID với một giá trị từ trình tự k cho đến khi hết ID băng tải. Các đai từ mỗi băng tải được gán cho tập con tương ứng, tạo ra các tập con.
5.2 Thuật toán mô hình hóa
Thuật toán đầu tiên được thử nghiệm là hồi quy tuyến tính bình phương nhỏ nhất thông thường, được chọn vì tính đơn giản và khả năng ứng dụng rộng rãi. Thuật toán thứ hai được thử nghiệm là một khu rừng ngẫu nhiên, được thực hiện trong gói R randomForest (Liaw và Wiener, 2002 ). Rừng ngẫu nhiên là một mô hình tổng hợp bao gồm một tập hợp các yếu tố dự đoán cây quyết định, mỗi yếu tố được đào tạo trên một tập hợp con ngẫu nhiên của dữ liệu đào tạo được lấy mẫu thay thế với kích thước bằng với kích thước của dữ liệu đào tạo ( mẫu bootstrap ).
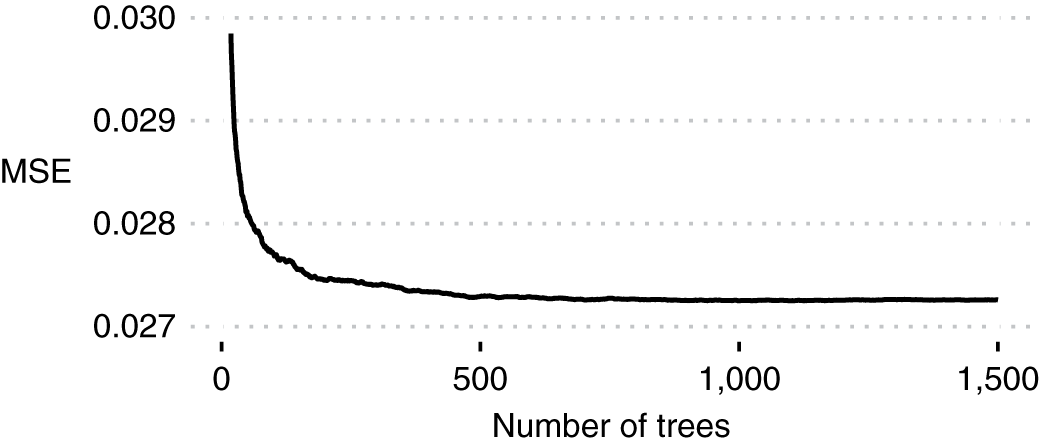
Có một số thông số của một khu rừng ngẫu nhiên mà có thể ảnh hưởng hiệu suất, bao gồm: ntree , số lượng cây trồng; mtry , số lượng biến ứng viên được chọn ngẫu nhiên để tách; và nodesize , kích thước tối thiểu của các nút đầu cuối. Các ntree tham số này được hiểu để tăng hiệu suất cho mô hình hồi quy với cây hơn với chi phí của thời gian tính toán, hội tụ đến tối đa ổn định ngoài mà thêm nỗ lực tính toán không đủ khả năng bất cứ cải tiến (Breiman, 2001 ). Lỗi OOB như một hàm của ntree đối với dữ liệu của chúng tôi được thể hiện trong Hình 9 , chứng tỏ rằng một bình nguyên đạt được sau khoảng 500–1.000 cây. Chúng tôi đặt đến 1.000 mà chi phí tính toán không quá cao đối với dữ liệu và phần cứng của chúng tôi.
Hình 9.Sai số dự đoán ngoài túi như một hàm của số lượng cây trong khu rừng ngẫu nhiên. Tại mỗi thời điểm, 100 khu rừng được trồng và các sai số được tính trung bình để tạo ra một đường cong mượt mà. Lỗi giảm đơn điệu và đạt đến mức ổn định.
Giá trị tối ưu của mtry được tìm thấy trong mỗi khu rừng ngẫu nhiên được huấn luyện được thể hiện trong Bảng 3 . Đối với dữ liệu của chúng tôi, giá trị 1 là tối ưu trong khoảng 80% rừng, tương đương với việc chọn ngẫu nhiên một biến tại mỗi nút để tách khi trồng cây hồi quy và giảm thiểu mối tương quan giữa các cây trong rừng. Hàm tuneRF bắt đầu bằng , (trong đó là số biến giải thích và là hàm tầng trả về phần nguyên của một số thực) và tìm kiếm bằng cách thổi phồng và làm giảm giá trị này theo hệ số 2, đó là lý do tại sao 3 không xuất hiện trong kết quả.
Bảng số 3.Tính ổn định của các giá trị mtry tối ưu , số lượng biến được lấy mẫu ngẫu nhiên làm ứng viên ở mỗi lần chia khi cây phát triển.
Thông số này được điều chỉnh để giảm thiểu lỗi hết túi trên dữ liệu đào tạo trong mọi lần xác thực chéo. Giá trị là 1 gần 80% thời gian.
Bởi vì điều chỉnh mtry là một phần của quá trình đào tạo mô hình, trong thực tế khi đào tạo một khu rừng ngẫu nhiên trong cài đặt sản xuất sử dụng tất cả dữ liệu, mtry không nên được cố định thành 1; thay vào đó, quá trình điều chỉnh tương tự phải được lặp lại. Phân tích phân phối các giá trị tối ưu vẫn mang tính thông tin và cung cấp một thước đo về độ ổn định của mô hình.
6 Kết quả và thảo luận
Phần này trình bày kết quả của khung đánh giá mô hình và cung cấp một số hiểu biết về mối quan hệ đã học được giữa tốc độ hao mòn và các biến giải thích của rừng ngẫu nhiên.
6.1 Dự đoán lỗi
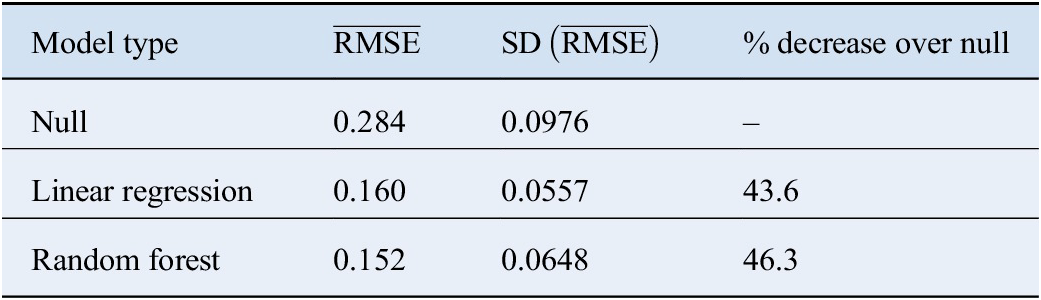
Giá trị hàm tổn thất trung bình của mẫu (thống kê xác nhận chéo), SD mẫu của các giá trị tổn thất và phần trăm cải thiện trong RMSE so với mô hình rỗng không có thông tin được tóm tắt trong Bảng 4 . được tính toán trên các giá trị tổn thất trung bình cho mỗi bộ thử nghiệm, được tổng hợp qua mỗi lần lặp lại quá trình xác nhận chéo (tổng các giá trị) để đo độ ổn định của hiệu suất.
Bảng 4. Dự đoán kết quả hoạt động.
Cả rừng ngẫu nhiên và hồi quy tuyến tính đơn giản đều hoạt động tốt hơn mô hình rỗng, chứng tỏ rằng các biến giải thích chứa thông tin dự đoán về tốc độ hao mòn tổng quát cho các băng tải ngoài mẫu. Rừng ngẫu nhiên hoạt động tốt hơn hồi quy tuyến tính đơn giản ( 0,152 so với 0,160), mặc dù sự khác biệt (7,75 × 10 –3 ) nhỏ hơn nhiều so với SD của sự khác biệt (2,97 × 10 −2 , được tính trên các cặp RMSE), gợi ý là không sự khác biệt giữa hiệu suất của hai phương pháp.
Rừng ngẫu nhiên có giá trị trung bình , được tính toán dựa trên dữ liệu thử nghiệm qua mỗi lần phân tách xác thực chéo ( ). Điều này cho thấy rằng mặc dù mô hình có hiệu quả trong việc sử dụng thông tin từ các biến giải thích để thu hẹp phạm vi tỷ lệ mòn đai có khả năng xảy ra , nhưng vẫn còn một lượng lớn phương sai không giải thích được, cho thấy rằng có thể có những yếu tố khác không có trong dữ liệu của chúng tôi có thể được thu thập để đưa ra các dự đoán tốt hơn.
6.2 Tầm quan trọng và tác động thay đổi
Mặc dù mục đích chính của chúng ta khi lập mô hình trong vấn đề này là dự đoán chứ không phải suy luận, nhưng nó thường là mong muốn hoặc thậm chí là điều cần thiết để các dự đoán của mô hình có thể giải thích được. Nó cũng hữu ích để hiểu tầm quan trọng tương đối của các biến đầu vào và cách chúng liên quan đến các giá trị dự đoán. Một phương pháp để đánh giá tầm quan trọng của các biến có thể được áp dụng bất kể việc lựa chọn thuật toán là phương pháp hoán vị.
Phương thức hoán vị lấy một thể hiện mô hình được huấn luyện và tiến hành như sau.
1. Tính toán tổn thất (RMSE) trên một tập dữ liệu không thấy được trong quá trình đào tạo.
2. Xáo trộn (hoán vị) các giá trị của một biến giải thích duy nhất và tính toán lại tổn thất trên cùng một dữ liệu bằng cách sử dụng các giá trị được xáo trộn.
3. Lưu trữ sự mất mát suy giảm sau khi xáo trộn, khôi phục thứ tự ban đầu của các giá trị và lặp lại quy trình cho các biến giải thích còn lại.
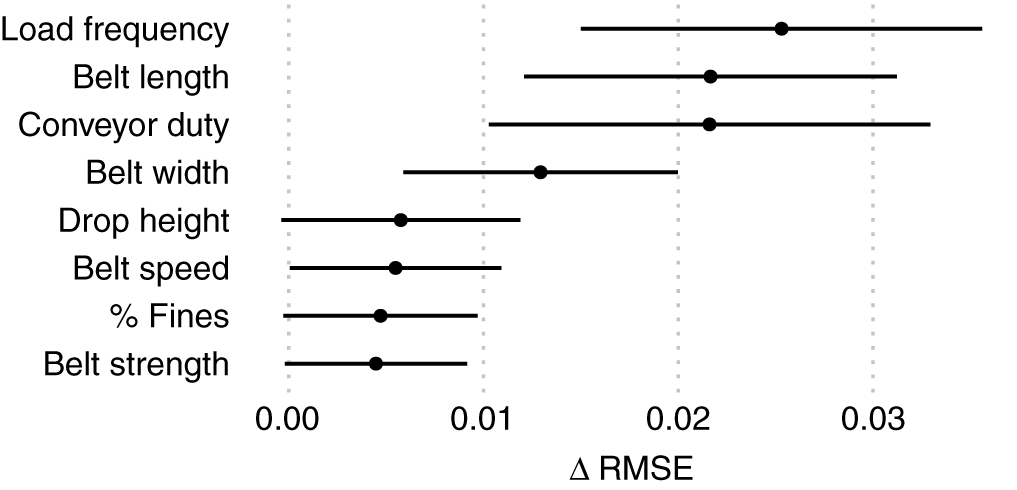
Một phiên bản của phương pháp này được thực hiện bởi gói randomForest sử dụng dữ liệu OOB. Tuy nhiên, như đã thảo luận trước đây, dữ liệu OOB vẫn có thể bao gồm các băng tải được thấy trong quá trình đào tạo có thể dẫn đến sai lệch. Thay vì sử dụng phương pháp này, chúng tôi sử dụng lại quy trình xác thực chéo lặp lại và chứng minh một cách tiếp cận tương thích với bất kỳ thuật toán nào. Các bước của phương pháp hoán vị được lặp lại trong mỗi phân vùng xác thực chéo và sự khác biệt trong RMSE trước và sau khi hoán vị mỗi biến giải thích được lưu trữ dẫn đến các giá trị cho mỗi biến. Giá trị trung bình và SD của sự thay đổi trong mô hình RMSE đối với rừng ngẫu nhiên được thể hiện trong Hình 10 .
Hình 10.Các kết quả về mức độ quan trọng của hoán vị, được thể hiện dưới dạng sự suy giảm trong RMSE do xáo trộn từng biến. Giá trị lớn hơn cho thấy biến quan trọng hơn đối với độ chính xác của dự đoán. Các đường thể hiện một SD trong số mỗi bộ thử nghiệm trong xác nhận chéo.
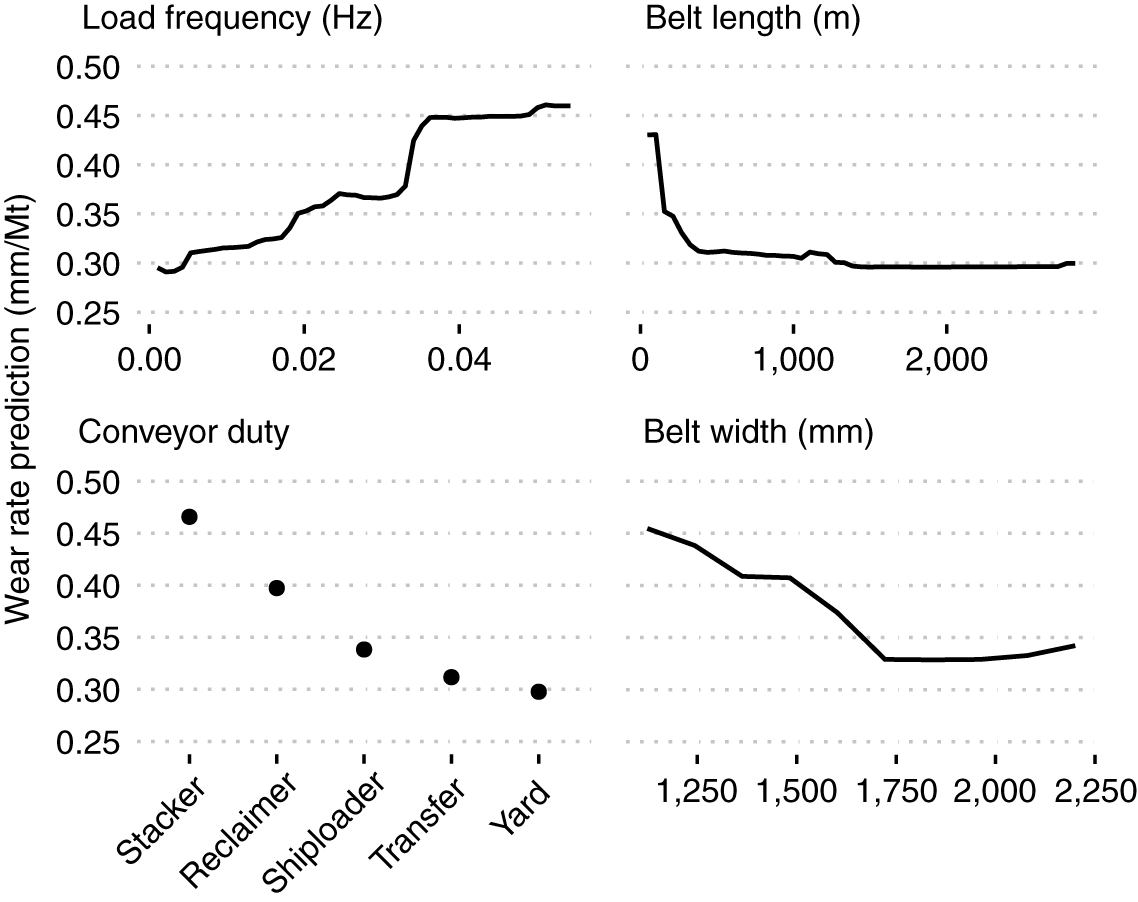
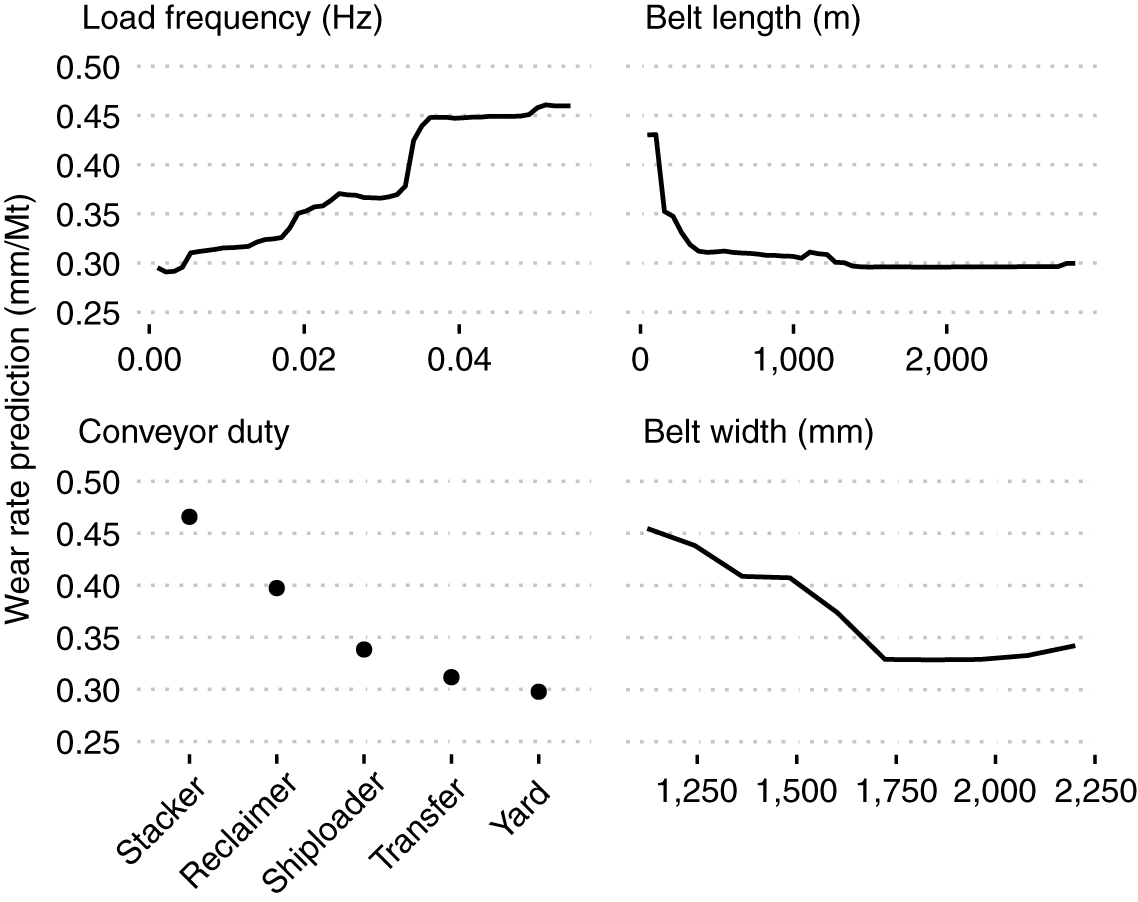
Cuối cùng, để cung cấp một số thông tin chi tiết về mối quan hệ giữa các biến quan trọng nhất và tỷ lệ hao mòn dự đoán, các đồ thị phụ thuộc một phần được thể hiện trong Hình 11 được tạo bằng cách sử dụng gói pdp cho R (Greenwell, 2017 ). Các số liệu này tương ứng với một mô hình rừng ngẫu nhiên với các thông số cố định và . Các tác động chung của nhiệm vụ băng tải kết hợp với tần suất tải, chiều dài băng tải và chiều rộng băng tải đã được kiểm tra, cùng với các ô kỳ vọng có điều kiện riêng lẻ (Goldstein và cộng sự, 2013 ), không cho thấy sự hiện diện của bất kỳ tương tác đáng chú ý nào. Do đó, chỉ các đồ thị phụ thuộc một phần của dự đoán duy nhất được hiển thị.
Hình 11. Các ô phụ thuộc một phần của mô hình rừng ngẫu nhiên với bốn biến số hàng đầu.
Hình 11 cho thấy tốc độ mòn dự đoán tăng lên với tần số tải lớn hơn và giảm đối với các dây đai dài hơn và rộng hơn. Băng tải xếp chồng có tỷ lệ mài mòn cao nhất trong số các cấp độ làm việc và băng tải bãi có tỷ lệ mài mòn thấp nhất. Phạm vi kích thước ảnh hưởng đối với tần suất tải và nhiệm vụ của băng tải tương tự và lớn hơn đối với chiều dài và chiều rộng của băng tải. Kích thước ảnh hưởng tương đối lớn của tần số tải và mối quan hệ tuyến tính hợp lý của nó với tốc độ mài mòn, cùng với việc thiếu các tương tác đáng chú ý có thể giải thích tại sao sự khác biệt về hiệu suất giữa rừng ngẫu nhiên và mô hình hồi quy tuyến tính là nhỏ.
7 Kết luận
Dữ liệu độ dày vành đai siêu âm, mặc dù có độ phân giải tương đối thấp, hiển thị các kiểu mài mòn thường tuyến tính mạnh trong suốt thời gian tồn tại của vành đai. Việc kết hợp những dữ liệu này với hồ sơ theo dõi vật liệu hỗ trợ các số liệu dựa trên thông lượng, mạnh mẽ hơn trong các trường hợp việc sử dụng băng tải không nhất quán.
Chúng tôi đã đào tạo mô hình hồi quy tuyến tính và mô hình rừng ngẫu nhiên để tìm hiểu mối quan hệ giữa các thông số kỹ thuật của băng tải và tỷ lệ hao mòn trong trường hợp xấu nhất tổng quát cho các băng tải ngoài mẫu. Phương pháp rừng ngẫu nhiên hoạt động tốt hơn một chút, với (tốt hơn 46,3% so với mô hình không thông tin không có biến giải thích) và giá trị trung bình là 0,58 trên băng tải không nhìn thấy. Điều này giúp cải thiện khả năng dự đoán tỷ lệ hao mòn của việc lắp đặt băng tải mới hoặc đối với những băng tải không có dữ liệu về độ dày.
Mục tiêu của công việc này không nhằm loại bỏ nhu cầu kiểm tra độ dày đai thường xuyên; đây sẽ là một đề xuất rủi ro ngay cả khi các mô hình cung cấp hiệu suất dự đoán tốt hơn. Tuy nhiên, lợi ích của các mô hình dự đoán này vượt ra ngoài ước tính thời gian sử dụng hữu ích còn lại. Ví dụ, mô hình có thể được sử dụng để xác định và nghiên cứu đai đeo nhanh hay chậm bất thường so với dự đoán, để nâng cao hiểu biết về độ mòn của đai và nhân rộng các phương pháp hay nhất, do đó nâng cao hiệu suất của nhà máy. Ngoài ra, việc xây dựng các mô hình dự đoán được hưởng lợi từ dữ liệu chất lượng cao, dễ truy cập sẽ thúc đẩy các phương pháp tốt nhất để thu thập và quản trị dữ liệu. Chúng tôi tin rằng có rất nhiều cơ hội để cải thiện hiệu suất dự đoán. Công việc trong tương lai có thể tập trung vào: (a) các biến số mới, ví dụ, vận tốc của vật liệu so với đai tại khu vực chất tải,Hình 1 ; (b) độ phân giải cao hơn và dữ liệu độ dày vành đai thường xuyên hơn; (c) dữ liệu vận hành băng tải chuỗi thời gian từ hệ thống SCADA; (d) đặc tính tốt hơn của tải, ví dụ, tấn trên mét, tấn trên chu kỳ đai; và (e) thử nghiệm các thuật toán khác.